I don’t put paid work on here as typically it won’t be things that are undertaken at my behest, performed mostly by me, or that I actually have the legal ability to talk about at all. I will make an exception for Graphia though.
Towards the end of 2012, getting frustrated with the shifting sands of working in a consultancy (from which I was on an unpaid sabbatical anyway, for reasons), I started looking around for other work. I came across an advert for a job at Edinburgh University’s Roslin Institute that sounded a lot like some work I’d done as an undergrad. I went for an interview and was offered the job. It turns out that I had misunderstood the original advert’s invitation to help develop “[the] next generation [of] sequencing software” to mean rewriting and improving upon an existing bit of software, whereas what it actually meant was to develop Next Generation Sequencing software. Oh well, it was a 2 years of guaranteed employment (on contract) with decent-ish money and minimal stress. I thought I’d see it out and then look again.
As I understand it, the Java based predecessor software that I had been tasked with working on was originally written as a means to an end, and (from memory) had since been through at least half a dozen software engineer owners, I assume few or none of which felt they had particularly strong ownership over it. The latest of these custodians seemed particularly eccentric, eschewing the use of any source control or standard build system software whatsoever, and having a particular penchant for creating data structures comprised solely of multi-level nested Tuples. As I understand it they were “encouraged to move on” over some unrelated unprofessional behaviour. Anyway at this point I was getting that pit-of-your-stomach, what-have-I-got-myself-into-here feeling. It took me a full working month to get the thing building at all (for it had no means of doing so included with the source), and I was considering my employment options. It was also about this point when I discovered a frighteningly stupid construct along the following lines.
public class Main {
public static void main(String[] args) {
try {
AnotherMain.main(args);
} catch (Exception e) {
// Ignore all exceptions
}
}
}
Of course I immediately unignored exceptions, and subsequently received a steady stream of complaints from users that it now crashed frequently. It was then that I knew there was basically no hope of meaningfully rescuing the project. Nevertheless (and in part down to an otherwise pleasant working environment) I persevered and made various modest feature improvements, but most of what I did with it was stabilising the Jenga tower of technical debt that it had accumulated over its decade or more of existence.
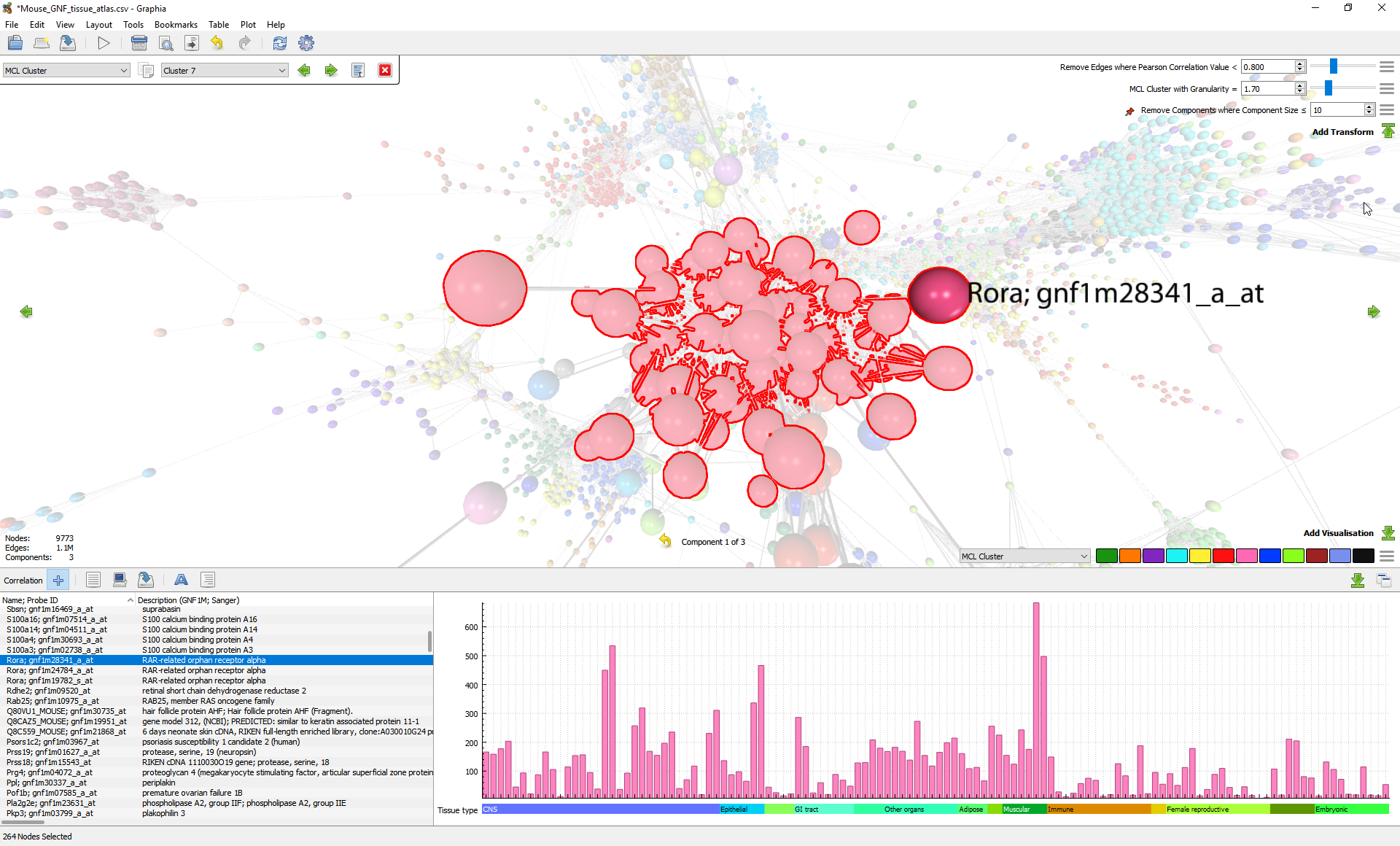
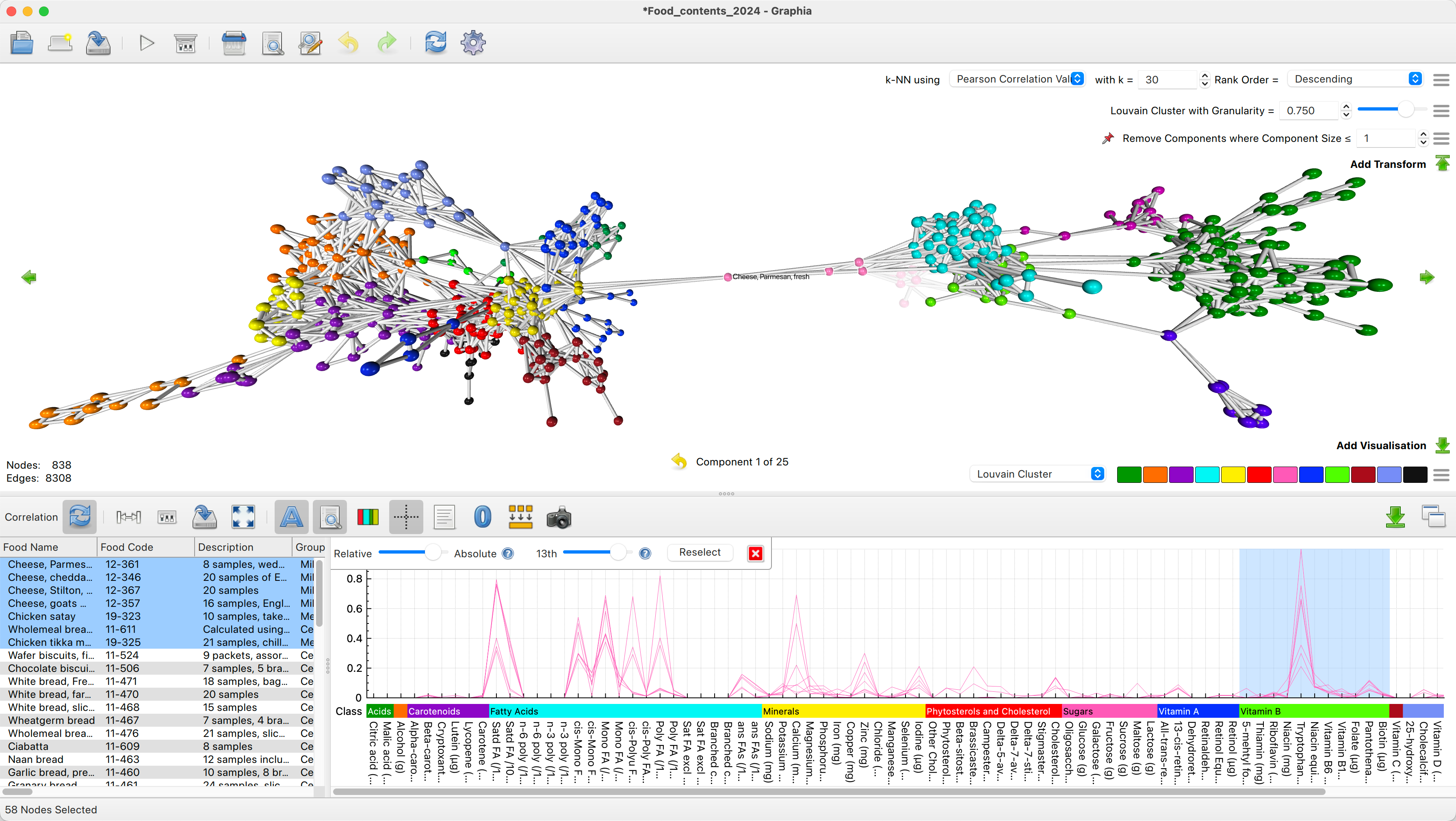
I should probably explain what this software did. Essentially it visualised data in the form of a graph, where by graph I mean in the strict mathematical sense of nodes joined by edges, also sometimes referred to as a network. Such graphs are often used to model relationships between things, where the nodes signify the things and the edges the relationships, for example you could represent London underground tube stations by nodes, and the lines that joined them as edges. In the biological sciences, often experiments produce large quantities of data that is relatively speaking impenetrable at face value. It can of course be statistically analysed for patterns in various ways, but what these approaches typically lack is in providing a intuitively digestible overview of the data as a whole. Humans have obviously not evolved to be able to readily interpret big tables of numbers easily, this skill not being particularly useful in avoiding predators on the plains of Africa. Instead we’re much better at digesting information visually, our intuition finely tuned over millennia to quickly pick out salient details or anomalies from an image, in a way that simply isn’t possible when regarding the raw data. In particular the approach the software took was to process a table of data row wise, comparing each row with every other row using a correlation metric. Each row was then represented graphically as a node, and if the computed correlation score relative to another row was above a certain threshold, an edge was drawn between them. There’s more to it in terms of how you position said nodes and otherwise interact with the visualisation, but those are the basics.
A year or so into the contract, having already completed the underlying task on which my position was funded and having not been given any further tasks of any significant note, I started twiddling my thumbs somewhat. I then wondered if I might just have a stab at doing the job I had originally misunderstood it was that I had. So I broke out the right tools for the job and started coding up a little prototype graph renderer from scratch, which I then generically named GraphTool. I took a pragmatic approach here, using a simple instancing mesh renderer, knowing that I would be able to swap it out for a more efficient ray-casting/smart-culling approach in the future, but regardless it was already probably an order of magnitude more capable than the old software, and impressed everyone that saw it. The main advantage it would have over its predecessor and competitors was the live layout aspect, where graph construction parameters could be adjusted and visualised in near real-time, avoiding the time consuming complete rebuild that was previously required. This closed the analysis loop somewhat, enabling faster interpretation of larger data sets.
I tinkered with it some, and amongst my other work it went in and out of the foreground a few times. The 2 years of my contract were almost up and extending my position through academic grant funding was looking unlikely. Coincidentally, in 2014 the university was keen to create spin-out companies and one way or another the software on which I was working had come to the attention of the staff whose job it was to facilitate this. To cut a very long story short, Kajeka Limited was formed. Its mission was to commercialise both the existing old software and provide a vehicle with which to further develop my little experiment. I think even today the people involved in the company would disagree over its primary purpose, but the reason I agreed to be involved was firmly the latter. During a long 5 or so years in which our funding was both minimal and somewhat drip-fed, we made a decent fist of it. Graphia, as it was now known, eventually reached a minimal-viable-product stage, but by this point our investors had lost confidence in the project. For such a niche product, the only realistic route to profit was targeted low volume sales at a very high ticker, and we never managed to meaningfully connect with any willing customers. I do wonder if things would have been different if we had used our meagre resources a bit more efficiently and made more, earlier progress on Graphia, but we’ll never know. Besides, at the end of the day I’m sceptical that a software sales market exists for it; we never managed to find one, at any rate. That’s not to say it’s without value, but in an age where a huge fraction of software is essentially free at the point of use, it’s a very hard sell.
Following Kajeka’s demise there ensues another long story that I won’t bore you with, suffice it to say I was able to continue working on Graphia for a further 4 years, this time under the auspices of a big-pharma company. We had now made Graphia open source and in part thanks to some advertising it gained a new academic user base, which it seems to have retained to this day.
Thanks to the decade or so or paid time I was able to put into it, Graphia is by far the most I have ever contributed to a single bit of software and its something I’m quite proud of. The code is internally consistent, well organised and although there are a few sharp edges here and there, fundamentally it’s good engineering. Ultimately, for reasons, I wasn’t ever able to take it in the direction I really wanted to, not least in the temporary mesh based renderer I alluded to earlier, a case in point of “there is nothing more permanent than a temporary solution”. I’d also have liked to have made it a bit less niche and broaden its appeal, by enabling third parties to develop their own analysis methods; as it stands it really only does correlation analysis well and (quite reasonably) this primary use case always won out. Regardless, it’s open source now so if these itches ever get too itchy and I have the time, I am able to scratch them.